Алгоритмы машинного обучения в сервисах для исследования генеалогии
За последние годы искусственный интеллект произвел революцию почти во всех отраслях повседневной жизни — от науки до сферы развлечений. Сегодня использование AI-алгоритмов перестало быть прерогативой технологических гигантов: разные области ИИ, включая data science и machine learning, все сильнее проникают в малый и средний бизнес и помогают обрабатывать большие объемы данных для решения разных задач.
Ранее мы писали про алгоритмы классического машинного обучения и принцип работы нейросетей. С 2018 года SimbirSoft активно использует machine learning для достижения бизнес-целей клиентов. В нашем портфолио — проекты для лесной промышленности, безопасности и других отраслей. В этой статье мы расскажем, как мы применяем свои знания по ML для разработки сервиса по исследованию генеалогии.
Наш клиент — крупная американская компания, работающая на рынке более 40 лет. Она развивает несколько IT-сервисов для сбора информации о генеалогическом древе семьи, обработки архивных документов и фотографий. Мы приняли участие в реализации нескольких подпроектов заказчика на основе машинного обучения.
Извлечение данных из архива старых газет
Продукт заказчика позволяет изучать родственные связи: пользователи сервиса указывают информацию о своих родственниках, и на ее основе формируется генеалогическое древо семьи.
Клиент располагает огромным массивом отсканированных газет, самые ранние выпуски которых относятся к XIX веку. В рамках проекта было необходимо извлечь из этого массива нужные данные, а именно — информацию о свадьбах. Для решения задачи мы разработали ML-алгоритм, который позволяет определить, есть ли на конкретной странице объявления о свадьбах, и классифицировать полученную информацию: дату события, имена невесты, жениха и гостей, место проведения церемонии, локацию медового месяца и другие данные, которые помогают подписчикам сервиса в составлении своего генеалогического древа.
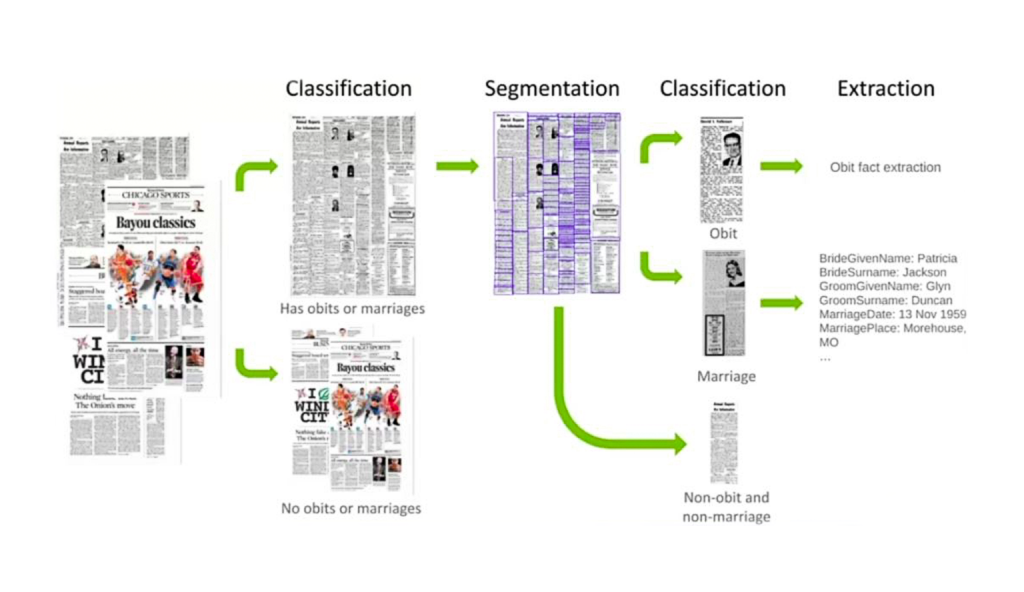
На этом проекте мы выполнили следующие задачи:
- Разработка универсального контроллера для массовой обработки сообщений.
- Разработка автоматически масштабируемой архитектуры.
- Разработка автоматизированной системы тестирования.
- Разработка универсального фреймворка развертывания приложений в облаке.
- Развертывание 7 МL моделей в облачной среде.
- Анализ и оптимизация производительности.
Извлечение данных из переписей населения
Эти проекты направлены на извлечение и обработку данных из переписей населения во Франции (1940 г.) и США (1950 г.). Нам предстояло в короткие сроки реализовать поставленные задачи с использованием наших наработок по Data Science. Информацию, полученную нами из рукописных текстов, пользователи сервиса теперь могут использовать для построения своего семейного древа.
По итогам проектов:
- 8,7 млн. страниц обработано
- 572 млн. записей извлечено
- Время обработки значительно сокращено: От 3 млн страниц/1 год (US1940) до 8 млн страниц/2 недели (US1950)
- За счет оптимизации производительности моделей и серверных мощностей сократились расходы на обработку изображений в 3 раза: с $27 млн до $9 млн
На обоих проектах мы выполнили следующие задачи:
- Развертывание и тестирование МL моделей в облаке.
- Повышение производительности системы за счет использования нескольких AWS регионов (дата-центров).
- Оптимизация производительности.
- Снижение затрат.
Восстановление и колоризация старых фотоснимков
Сервис позволяет восстановить старые фотографии и выполнить колоризацию черно-белых снимков. Эта функциональность была разработана для мобильных устройств. Благодаря ей функции приложения стали разнообразнее, продукт получил конкурентное преимущество и привлек новых пользователей.


На этом проекте мы выполнили следующие задачи:
- Разработка архитектуры обработки запросов в реальном времени.
- Реализация системы в сжатые сроки (3 сервиса, 1 месяц).
- Анализ и оптимизация производительности системы.
Выявление аномалий в работе системы
В работе продукта периодически возникают инциденты, влияющие на работу сервиса и, как правило, приводящие к снижению прибыли бизнеса. Для решения проблемы мы разработали ML-модель, которая анализирует поведение системы и ищет аномалии в ее работе. С ее помощью можно предсказывать «ненормальное» поведение системы и заранее оповещать системную службу.
На этом проекте мы выполнили следующие задачи:
- Анализ исходных данных.
- Оптимизация хранения массивов информации.
- Разработка ML-модели.
- Разработка архитектуры.
Результат
Вместе с партнером мы уже реализовали 8 важных продуктовых проектов и продолжаем сотрудничество. Мы гордимся тем, что наши разработки легли в основу корпоративного стандарта компании клиента. Также нам удалось сократить расходы заказчика за счет оптимизации использования ресурсов AWS.
Познакомьтесь с нашими решениями в области data science и другими кейсами в портфолио.


